前言:
ChatGPT自从推出后,其技术和便利性在全球掀起一篇热潮,ai取代各行各业的声音也越来越大,但也同时孕育了许多未来可能新生的行业,拥抱科技的同时,我们不外乎还是要考虑互联网安全性以及中心化滥权问题,当前ChatGPT虽然已经被奉为圭臬,但是其本质上还是中心化服务器,相关接口内容对于某部分的开发人员来说还是透明的,初期安全隐患暂不明显,或是尚未有人去强力反对,但可预测的是未来这些都是矛盾点:
-
透明的内容,您的相关问题和回答对于某部分人来说都是透明的,您的隐私、喜好、私人问题可能都会被不肖份子利用
-
中心化的服务器除了有故障风险外,还有可能因为地理位置等不同因素导致服务差异化
-
非自训练机器可能有主观意识形态主导,未来AI提供的内容如果受到部分团体控制可能会提供引导性回答
相对而言,自训练AI的好处刚好就在这几个方面的反向:
搭配nConnect传输,内容完全保密,不用担心你的私人问题和喜好被监控。
多节点服务器能够确保远程使用的时候不会因为单点故障而造成服务停摆。
自训练机器可以根据业务需求,培养公司或个人所需求的人格以及对话内容。
以下为架设详细流程:
操作步骤:
总体来说,操作分为两步,
A. 打通自己机器和外网的访问(将内网环境映射至公网),这个步骤需要通过nConnect完成
B. 在运算终端上(一般来说是带有高端显卡的电脑或服务器)安装人工智能语言(以ChatGLM为例)
A. 打通自己机器和外网的访问:
- 通过官方链接,安装nConnect server端以及client端
(https://nkn.org/products/nconnect/)
-
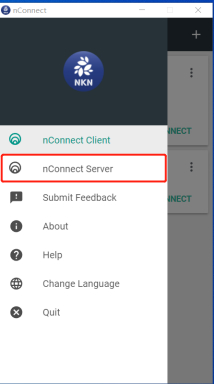
安装后,点击nConnect Server,点击start,待状态变为Connected后,点击Open web dashboard
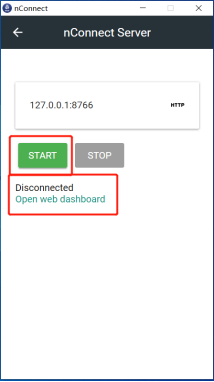
-
打开nConnect web 页面后,利用手机端扫码功能(中间图标或是右上角图标)进行链接以及配置同步
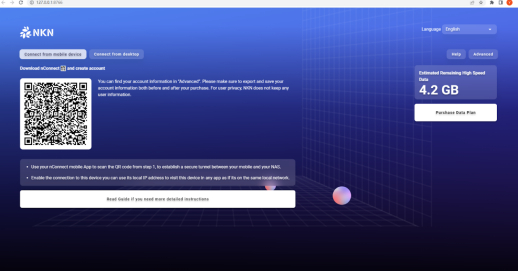
(Web)
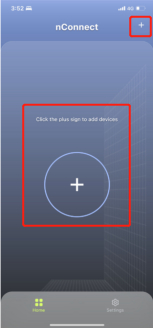
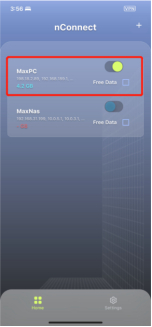
(手机端)
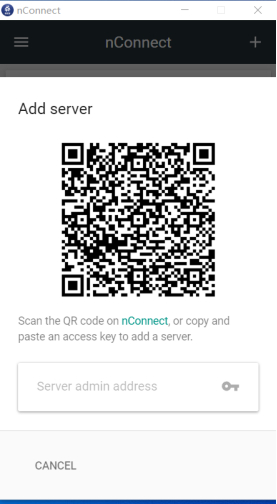
(PC端点击右上角,出现二维码后利用手机端扫码同步)
-
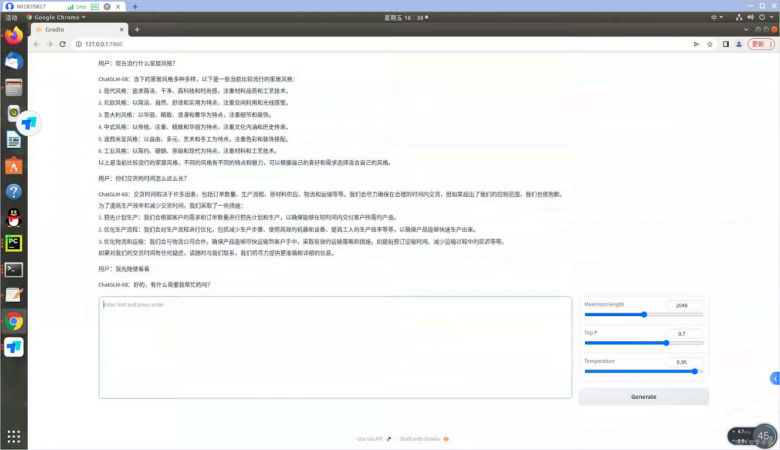
如果此时您已经完成了Chatglm 安装,请跳到B段内容的第8步骤,将Chatglm修改成内网可以访问后,直接从外网通过nConnect提供的内网IP和端口号,访问自建的人工智能语言
-
启动成功后,您就可以利用内网IP搭配端口号从外网访问Chatglm
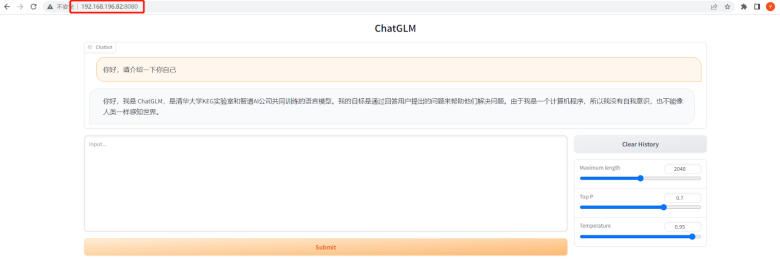
B. 在运算终端上安装人工智能语言
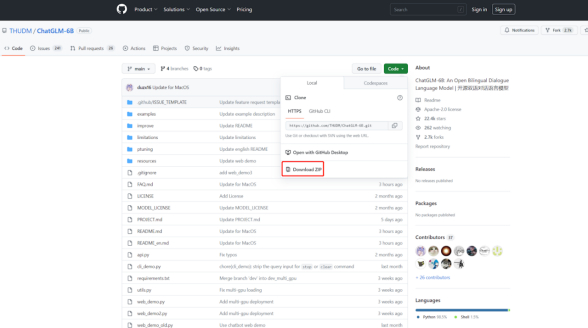
- 通过网址下载相关文件 https://github.com/THUDM/ChatGLM-6B
- 下载miniconda,用于配置基础算法环境。
这个是用来管理python版本的,他可以实现python的多版本切换。
下载地址:
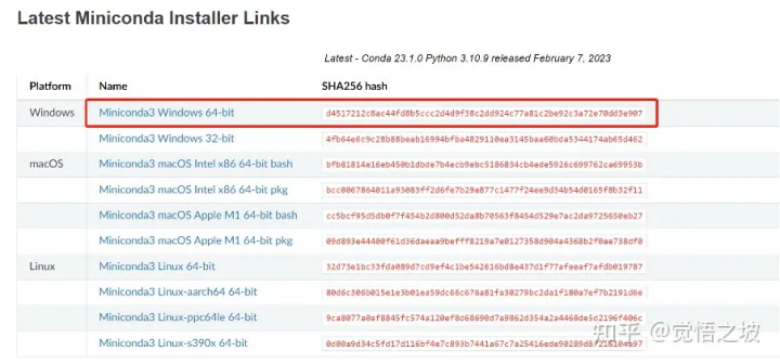
(miniconda下载截图)
安装时按默认的一路next就行。
- 打开miniconda,
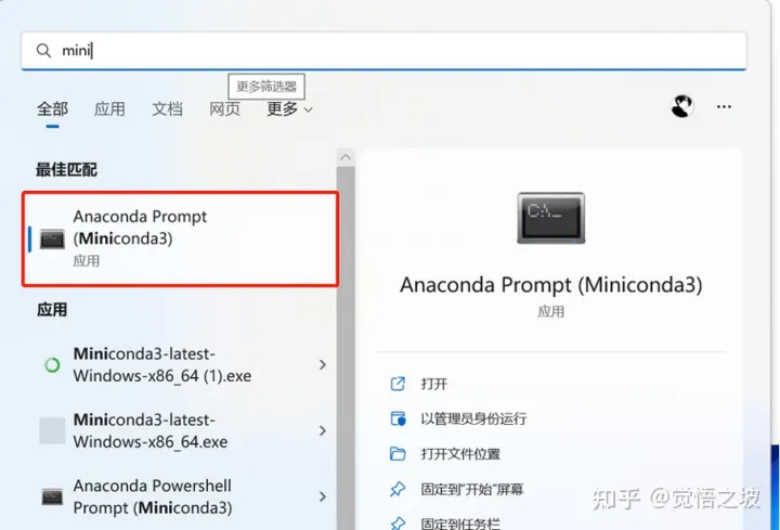
(开始-输入mini-找到miniconda3打开)
输入
conda -V
弹出版本号即为正确安装

(显示conda版本,那就对了)
- 安装CUDA
cuda是NVIDIA显卡用来跑算法的依赖程序,所以我们需要它。
打开NVIDIA cuda官网,http://developer.nvidia.com/cuda-toolkit-archive
(这里有人可能会打不开网页,如果打不开,请用魔法上网。)
你会发现有很多版本的CUDA,下载哪个版本呢?

回到一开始的miniconda的小窗,输入
nvidia-smi
查看你的cuda版本。
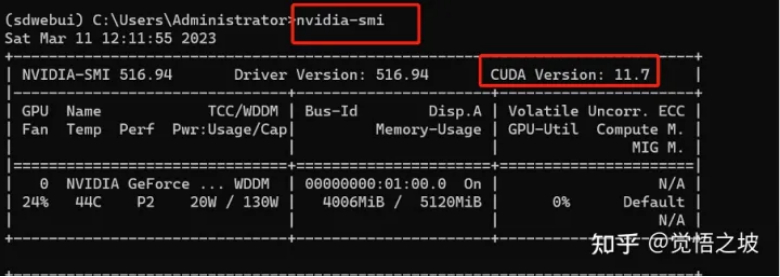
(在这里输入nvidia-smi的时候,有可能会显示“‘nvidia’ 不是内部或外部命令,也不是可运行的程序”。
这时候,需要确认你的显卡是否为Nvidia的显卡。
如果是,则检查自己的显卡驱动是否最新版,可以用鲁大师或者驱动精灵之类的软件更新驱动至最新。
如果更新驱动还不行,则把C:\Program Files\NVIDIA Corporation\NVSMI添加到系统环境变量。)
比如我的显卡cuda是11.7版本,所以我就下载11.7.1即可。
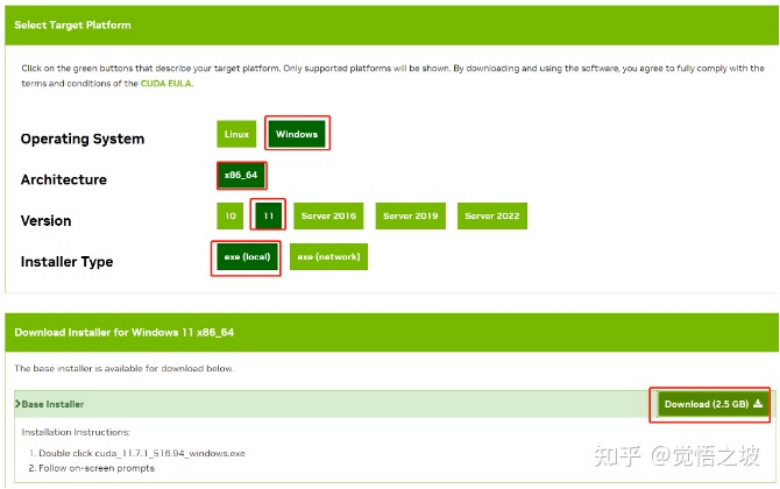
然后安装自己的系统选择win10或者11,exe local,download
下载完后安装,这个软件2个多G,可以安装在c盘以外的地方。比如D盘,节省系统盘空间。
好了,安装好之后,电脑的基础环境设置终于完事了。
- Cd 到刚才的资料夹
(小编的例子cd C:\Users\86186\ChatGLM-6B-main,读者请自行替换成自己的)
- 在文档中找到 web_demo.py 这个档案,并且使用记事本打开
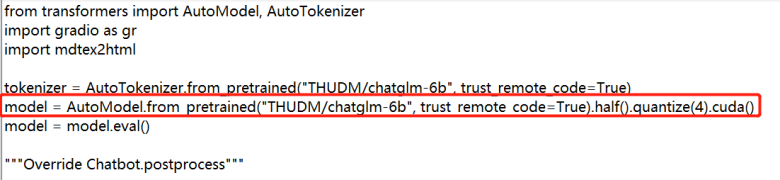
- 修改量化版本。如果你的显存大于 14G,则无需量化可以跳过此步骤。如果你的显存只有 6G 或 10G,则需要在第 5 行代码上添加 quantize(4) 或 quantize(8) ,如下:
6G 显存可以 4 bit 量化
model = AutoModel.from_pretrained(“model”, trust_remote_code=True).half().quantize(4).cuda()
10G 显存可以 8 bit 量化
model = AutoModel.from_pretrained(“model”, trust_remote_code=True).half().quantize(8).cuda()
修改后如图
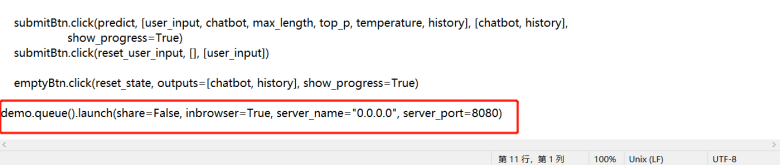
- 开放局域网访问权限,直接跳到 web_demo.py最后一行,添加参数server_name=“0.0.0.0”, server_port=8080
(熟悉的玩家可以自行修改端口)
-
此时,如果您已经完成nConnect安装,您可以直接在外网通过nConnect链接到内网的Chatglm中进行使用,详情请见A步骤的第4步。
-
创建执行chatglm 环境
conda create -n chatglm python==3.8
conda activate chatglm
- 安装依赖并执行命令 pip install -r requirements.txt
- 创建文件夹 chatglm-6b,并将训练后的模型加入(下载地址:https://huggingface.co/THUDM/chatglm-6b)
transformers 和 protobuf 库加载
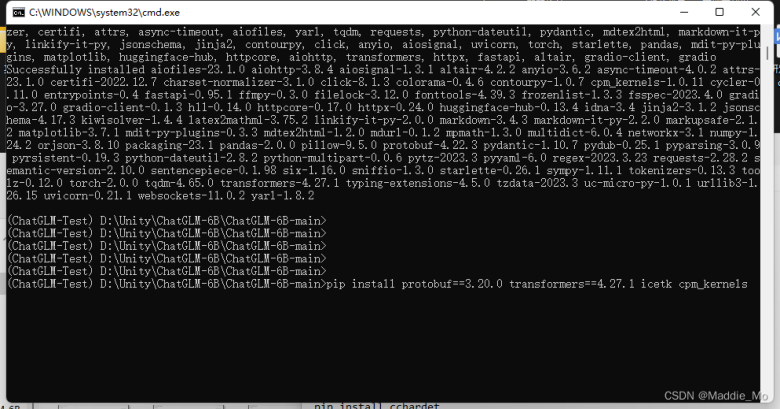
- 下载 protobuf 和 transformers 库支持
pip install protobuf==3.20.0 transformers==4.27.1 icetk cpm_kernels
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
pip install rouge_chinese nltk jieba datasets
加载 gradio库
pip install gradio
补充依赖库
pip install chardet
pip install cchardet
- 执行 代码python web_demo.py