

Introduction
NKN recently announced Stephen Wolfram - founder and CEO of Wolfram Research; author of A New Kind of Science (NKS); creator of Mathematica, Wolfram|Alpha, and the Wolfram Language - joined NKN as an advisor. Given Stephen’s pioneering discoveries using cellular automata , it was a natural fit that he become involved with NKN. We recently met with Stephen to explain exactly how NKN works and what makes it different than other blockchain applications.
In this lightly edited transcript of a recent interview, NKN’s CTO Yilun Zhang ( YZ ) and Dr. Stephen Wolfram ( SW ) explore how the NKN network can be simulated and visualized with Wolfram|One, details of NKN’s new breed of consensus algorithms based on NKS principles and cellular automata, and how improved consensus algorithms can be discovered for NKN and the asynchronous case.
To fully enjoy the interactive Wolfram notebook with all the embedded source code and graphing tools, here is a link to the cloud notebook (requires Version 12 of Wolfram Language for some functions):
https://www.wolframcloud.com/objects/outreach/Published/nkn-stephen-wolfram-interview
What is NKN?
SW
You definitely piqued my interest by calling your project NKN! And when I saw you’d listed me in the first two references in your white paper, I knew I really had to understand what you’d done. So I’m looking forward to hearing all about NKN.
From what I understand, you want to build a communications network that at least initially sits on top of the web, where you’re routing traffic through people’s computers, and compensating them with cryptocurrency for doing that. Is that right?
YZ
Yes, that’s right in terms of how people will use the network. But we’re trying to do something else as well, which is very relevant from the NKS point of view: we’re trying to make a new way for creating consensus, that’s local instead of global.
So, you see, we’re trying to build both a better internet and a better blockchain.
SW
That sounds pretty ambitious. Cool.
How Packets Move Through the Network
SW
Alright, so let’s get into how this works. So the basic thing I’d want to do on the NKN network is to send a packet from one address to another. The NKN network consists of a bunch of nodes — -which are computers that have NKN routing software running on them. The typical goal of the NKN network is to figure out how to send the packet from node to node to get it to arrive at the destination.
And I guess a big part is that the protocol has all sorts of crypto and blockchain parts. And as I understand it, this achieves two big things. First, it gives a way for communications to be private. And second, it provides a way of verifying whose computer got used to transfer packets, and so who should be paid cryptocurrency for doing that.
YZ
Yeah, so here’s a typical trace of how a packet traverses the network:
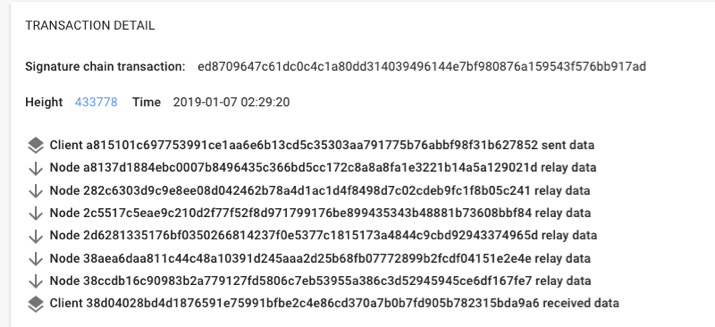
An example Signature Chain in NKN system
SW
What determines how many nodes this goes through?
YZ
Well, basically it’s roughly half the log of the number of nodes in the NKN network, where the base of the logarithm is related to the number of virtual neighbors of each node.
SW
What do you mean by virtual neighbors? I guess eventually you want the hops to be between nodes that are physically close in the underlying internet network. But I guess you mean something different by “virtual neighbors”…
YZ
Yes, the virtual neighbors are a certain kind of neighbor in NKN address space. Every NKN node is randomly assigned a fixed 256-bit unique identifier. Then what we want is two different things, that are in a sense in opposition. On one hand, we want to be able to route packets as directly as possible. But we also want to do it securely — -and to achieve that we want to add randomness to the path of the packet in such a way that a few bad actors can’t disrupt or manipulate it.
The scheme has a good tradeoff between efficiency and security. It’s an extension of the chord DHT (distributed hash table) method.
SW
OK, how does that work? Is there ultimately a fixed distance metric based on NKN addresses?
YZ
Yes. Given two NKN addresses a and b, the distance between them is just (b-a) mod 2²⁵⁶.
SW
OK, I think I have to break into code here. So let’s do a simple case, with 2¹⁶ instead of 2²⁵⁶. Let’s have 50 addresses of that type:

Now let’s define a nearest function:

OK, so with that function we can find out the 10 nearest neighbors of, let’s say, the first node in our list:

So are these the virtual neighbors you’d be using?
YZ
That’s one category of virtual neighbors. But there are two others as well. If we just used this first category, some packets would take an incredibly long time to get delivered. In fact, if we had k neighbors and n nodes altogether, it might be n/k steps.
So we add some intermediate “forwarding neighbors” to help us get packets delivered faster. These forwarding neighbors are based on adding 2^i to the addresses of each existing node, then seeing what nodes have addresses closest to that.
SW
Let me see if I understand. Let’s say we start from the first node in our list from before. Then we’d add 2^i (mod 2¹⁶) to its address:

Oh, for small i you’re not getting far enough away from the original node to reach another node. What do you do about that?
YZ
We just pick the unique nodes we reach.
SW
Ah, so it’s:

YZ
OK, there’s just one more step. We call the original nearest neighbors “successor” nodes. The third category of virtual neighbors are predecessor nodes, which are essentially just the inverses of the successor nodes, and the forwarding nodes.
By the way, when we figure out the successor nodes, we have about 2 log(n) of those, if n is the total number of nodes. We’ve found this is a good way to maintain robustness if a bunch of nodes go away.
SW
It would be fun to do an experiment and see how all this improves the routing efficiency. But what’s the answer?
YZ
Basically it makes typical packets be delivered in O(log(n)) hops. If you only used successor nodes, it’d be O(n) steps. You can actually prove the O(log(n)) result because with the setup we have, each hop effectively halves the distance…
SW
Why don’t we try to make a picture? First, let’s just arrange all the 2¹⁶ nodes in order around a circle. Then let’s see what nodes the very first node is connected to:

So, just as we set it up, the first node is connected to a bunch of nodes that progressively get exponentially further away, roughly speaking.
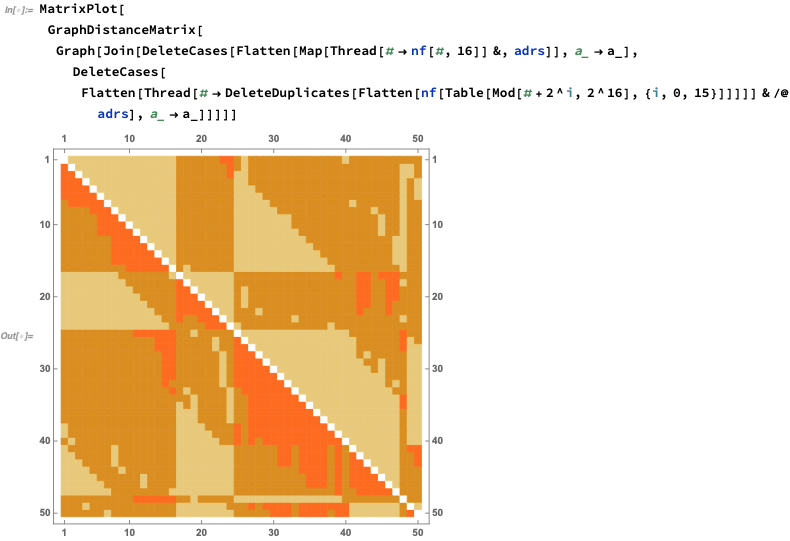
OK, so let’s see what this setup does for a whole network of nodes, say the 100 we randomly chose. To get a feeling for what’s going on, maybe we can start by seeing what would happen if we just connected each node to successively more neighbors:
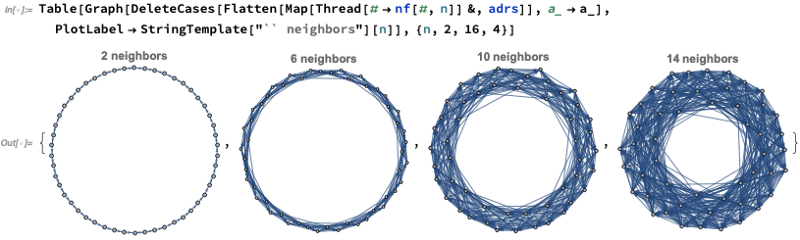
We can definitely always see the ring structure of the arrangement of nodes here — -which means it could take a long time for a message to get from one node to another.
But now let’s look at what happens by our 2^i “forwarding nodes” instead of nearest neighbors:

Now let’s combine these forwarding nodes with, say, nearest neighbors up to 16:
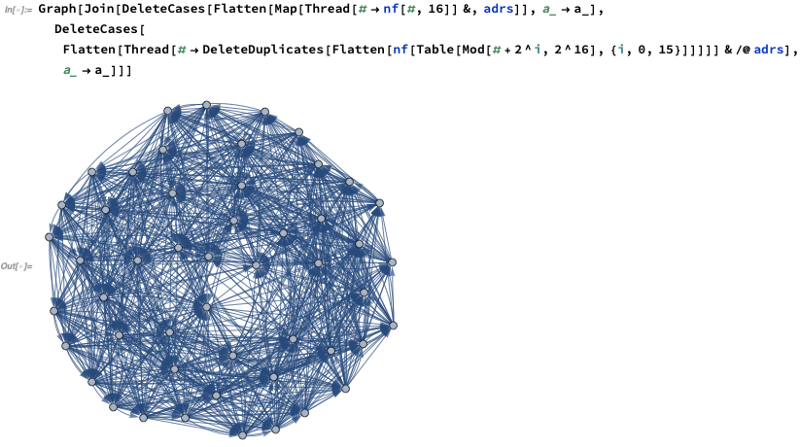
Obviously things are much better connected here. We can get a sense of how much better connected by making histograms of the number of steps needed to get from every node to every other node. So here’s a comparison neighbors, pure forwarding nodes, and the the combination:
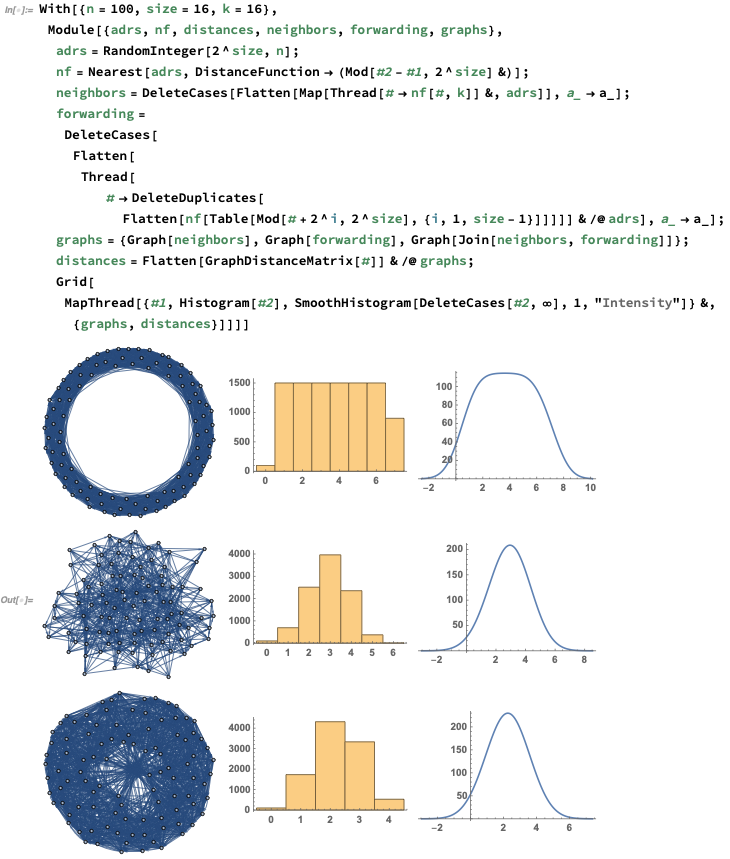
YZ
Yes, the distribution of network distances should be a Gaussian for the combination case — -and it looks like it is.
SW
And I guess I can see now why this method has the word “chord” in its name — -it has connections that go across the circle.
OK, but given a packet starting at a particular node, how does it actually route itself to its destination?
YZ
All it has to do is to take the address that it’s currently at, and go next to whichever of its virtual neighbors is closest to the destination. And basically at each step it’s going to end up roughly halving the distance in NKN address space that it is from its destination.
Recording What Happened, and Getting Consensus about It
SW
OK, so now we’ve talked a bit about how packets move through the NKN network. Let’s talk about the blockchain aspects of what you’re doing. As I understand it, you’re trying to create “signature chains” that are secure certificates that live in the header of a packet and show how the packet traversed the network. Is that right?
YZ
More or less. Actually, there can be a single signature chain for a sequence of successive packets.
SW
OK, so what gets put in the signature chain?
YZ
It’s basically a sequence of digital signatures together with node addresses. At each step, the chain records the address of the next node that will be visited, as well as a digital signature of that combined with the previous digital signature.
SW
So in code that would be something like this:

YZ
Yeah, though we use a slightly different elliptic curve and so on.
SW
Fair enough. But I gather there’s another blockchain involved as well?
YZ
Yes, it’s the blockchain that gives people credit for their nodes being used to relay packets.
And this is where the NKS stuff comes in. Because that’s what we’re using to find consensus for what blocks should be added to this blockchain.
SW
OK. So let me understand that. In a classic blockchain like Bitcoin or Ethereum you use proof of work to decide who gets to add the next block. In other words, you’re basically using what I call computational irreducibility — -in the particular form of solving a hash problem — -to set up a kind of computational race for who should be allowed to add the block. And the way this works is that miners compete to win this race, and as soon one of them reaches the finish line they broadcast their result to the network. Of course this whole thing wastes huge computational resources, and electricity.
And I guess that’s why some more modern blockchains are trying to move to “proof-of-stake” instead of proof-of-work, with the idea that nodes with more cryptocurrency should have a bigger chance to determine what the next block should be. How is that actually done?
YZ
A few years ago people were just making larger stakeholders have simpler problems to solve. But nowadays there’s a different approach used that’s based on directly forming consensus between nodes.
The first step is for all the nodes to agree on which one will be the proposer of the next block.
SW
So I guess that means they effectively have to use a protocol like the one for “coin tossing by telephone”…
YZ
Yes, that’s right. Though different blockchains use different versions of it.
SW
OK, but once everyone’s agreed on who will propose the next block, how is that block validated?
YZ
It needs consensus again. But now it’s typically just a consensus between “validator nodes.” And if those nodes reach consensus, then the block is added to the blockchain.
SW
Alright, but so how are you actually setting up consensus in NKN? I have a feeling this is where we’re going to get some NKS coming in.
YZ
Yes. The big thing we’re using is what we call MOCA: a “Majority vOte Cellular Automaton.”
SW
Ah, OK. Well, after so many years studying cellular automata, I’d better be able to explain to people what that is. Let’s start with the simplest version: a one-dimensional cellular automaton with two colors. We’ve just got a line of black and white cells, and at each step we’re updating the color of a particular cell on the basis of the colors of the cell on the previous step. Here’s an example of a rule we might use:

Starting with a single black cell, here’s the pattern one gets:

The patterns aren’t always as regular as that, but let’s not get into talking about that, at least not yet.
OK, but what’s the “majority vote” rule? In the numbering scheme I invented along time ago, it’s rule 232:

Whenever there’s more than one black cell in the neighborhood, the result is black. Otherwise it’s white.
So what happens if we start off with 80% black cells? The regions that are dominated by black quickly fill in as black — -but things get stuck:

Here’s a way to derive the rule number for the simplest majority rule:

If we allow next-nearest neighbors as well, this is the rule we get:

And once again, things get stuck:
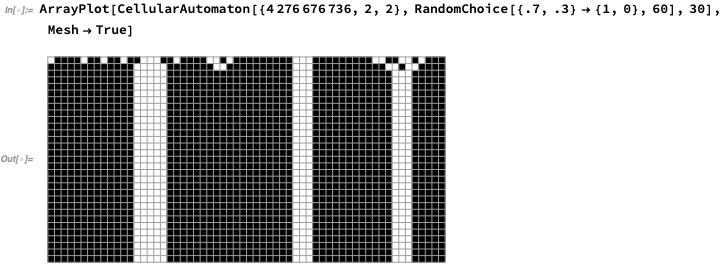
So, you might ask, is there any way to actually get consensus, in the sense that when there are more than 50% black cells in the initial conditions, the whole system becomes black in the end, and when there are less, it becomes white? Actually, this is a classic phase transition situation in physics. And there turn out to be cellular automata that are beautifully simple examples of this going on. Here’s a particularly clean one, from my NKS book.
If we start off from 70% black, every cell pretty quickly becomes black:
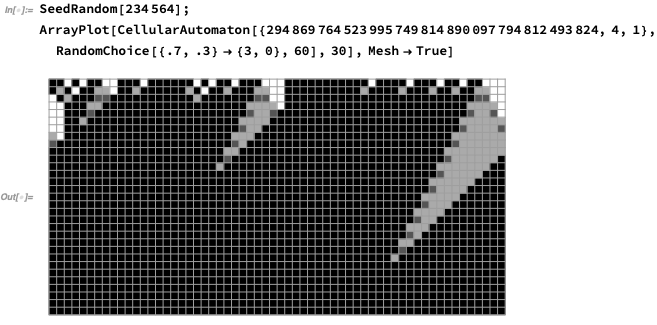
If we start with 70% white, everything becomes white:

Notice that there are those triangles that stick out, as the system “decides” what the dominant color will be. So what happens if it’s really close to 50% black, 50% white? Here’s a case with 52% black:

It eventually “decides” that the consensus value is black, but it takes a while. Actually, if you’re ε away from 50–50, it takes about ε^-ɣ steps, where ɣ is some constant. Right at the 50–50 point one has a “critical point” in the sense of statistical physics, and the system can take an infinite time “decide what to do,” producing a whole nested structure of partial decisions along the way:

In this particular rule, the “consensus decision” gets made in a very systematic — -and, one might say, plodding — -way. It turns out there are other rules that generate a bit of effective randomness, and where the “decisions” can be made faster, albeit slightly probabilistically.
OK, but in your actual network, you don’t just have a 1D array of cells; you have a network. Let’s get a bit closer to that by looking at a 2D array.
Let’s try a pure majority rule, operating on nearest neighbors. Here’s the rule, with the gray level showing the total value of all the cells in the neighborhood:

Here’s what happens if we start this from 70% black. It converges to “mostly black” but with a few “defects”:
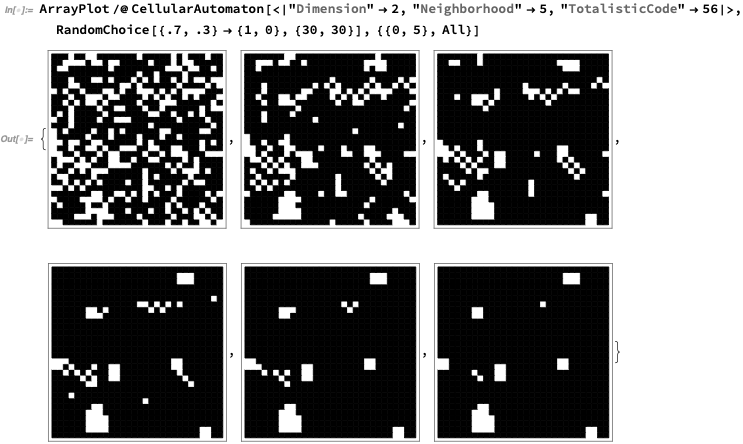
In 3D (2 dimensions of space, 1 of time) this is what’s going on (here showing 30% black):

This is looking “from the edge” and averaging:
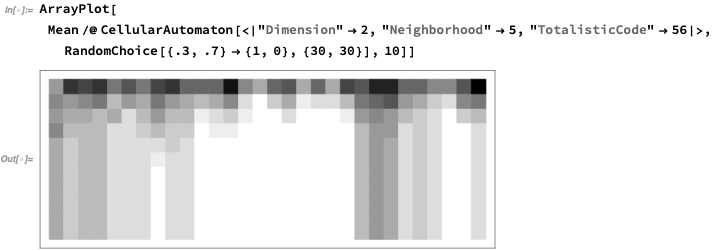
Here’s a bigger example, again showing a certain number of “defects”:

Here’s what happens if we use a slightly larger neighborhood:

When more cells are included in the working out the local majority, fewer “defects” tend to get left:
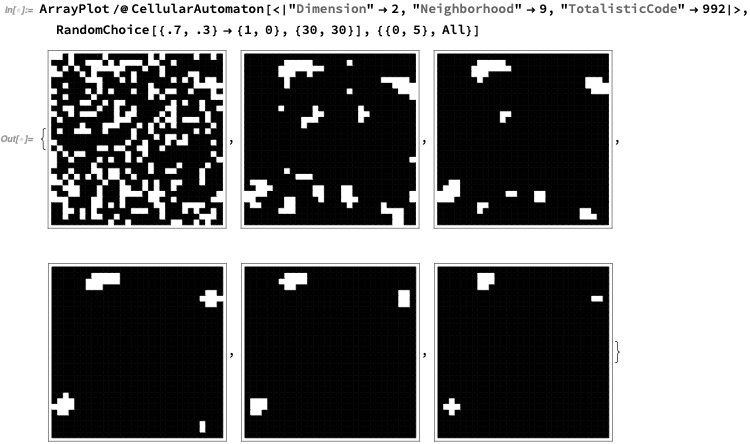
Here’s what it looks like “from the side” for 30% black:

OK, but are there better rules, that don’t leave “defects?” Here’s one that eventually does a decent job, though takes a while to “decide”:

Notice that it’s almost the majority rule, but with one change. After 5 steps it’s still definitely not “decided” what to do:

Here’s what happens if we go more steps:

Here’s the “view from the side”:

OK, so what about the network case? Instead of having all the nodes in an array, let’s assume they’re connected in one of your NKN networks.
(A totally connected graph will converge in one step.)
What about Malicious Nodes?
YZ
One complication in the real world is that not every node may be correctly running whatever consensus algorithm we specify. We could have malicious nodes that are running different algorithms, perhaps intentionally trying to mess things up.
SW
That’s like having a probabilistic cellular automaton, in which there’s a certain probability for a given cell to get updated according to a different rule. Do you want your malicious nodes to be fixed, or could they randomly move around?
YZ
To start off, let’s assume that a node is either OK, or malicious, and stays the same forever. Later, we can think about what happens if a node can change.
The attack model we consider is as follows. There are M malicious nodes out of N nodes. An attack is successful is the malicious nodes can force the consensus to converge to the minority instead of majority of the honest nodes’ initial state. Malicious nodes can send out arbitrary vote to their neighbors, not following the consensus protocol, but they cannot change their neighbors because the topology we choose is verifiable. The reason we consider this attack model is that, if an attacker can force the honest nodes to converge to the minority state, then they can essentially control the consensus result, either letting it converge to any state, or making it not converge at all.
What we found is that whether an attack is successful or not depends on two parameters: how many malicious nodes in the system and the distribution of honest nodes’ initial states. For example, if all honest nodes are initially in the same state, then we need quite a lot malicious nodes, actually around N/3, in order to force all honest nodes to change their opinion. However, if honest nodes have a quite balanced initial state, then just a small number of malicious nodes are enough to break the balance towards any direction and, thus, control the consensus result. We call such a property conditional-BFT (Byzantine Fault Tolerant) — -that is, whether the consensus is BFT or not depends on the initial condition. We end up using other parts of the system design to help the network stays in the BFT region.
Making the Network Efficient
SW
So if you want to prevent malicious nodes from disrupting the network, you need to randomize the route. This seems inefficient in terms of the shortest and fastest path to send a packet.
YZ
There are some efficiency and security tradeoffs. However, we can actually make NKN routing better than current Internet routing. Each link between NKN nodes knows its ping time, so from a given node, you can pick the node with the lowest latency.
In addition, you can create multiple concurrent NKN routes between sender and receiver. This way, you can even aggregate bandwidth of all the virtual paths. Recently we did a prototype of a web accelerator and achieved a 167% — 273% speed boost by doing so. And the bigger the file, the better the boost. It shows us that the bottleneck for web downloads is neither at the content server nor the user’s ISP, but rather in the middle of the default network routing path.
The Implications
SW
OK, so if all this works according to plan, what can you do with it? It seems like you could make a better version of something like Bit Torrent. Is that right?
YZ
We can enable a lot of applications to communicate directly without any centralized servers. Some of the low hanging fruit is instant messenger, web proxy and relays, live video streaming and sharing, dynamic Content Delivery Network (CDN), for example.
In principle, any application that requires user-to-user communication. Therefore we believe the potential of NKN is boundless, and we are really happy you and the Wolfram team can help us achieve our ambitious goal.
Conclusion
The key takeaways from this interview are:
-
NKN uses a novel packet routing protocol based on Chord DHT , which can be simulated and visualized as an overlay network with “chords” by Wolfram|One . This has general implication to all blockchain projects: protocol designers can now use the powerful tools of Wolfram|One to mathematically prove, simulate, and improve algorithms without burning thousands of dollars’ worth of cloud computing costs in running large-scale testnets.
-
NKN is creating a new breed of consensus algorithms that is both extremely scalable and efficient , based on NKS principles in general and cellular automata rules in particular. The traditional consensus algorithms by competing hashing power is an interesting and surprising twist of Stephen Wolfram’s computational irreducibility principle found in NKS and foreseen 30 years ago.
-
Stephen Wolfram believes by exploring the computational universe further through NKS principles and methods, we can discover even better consensus algorithms for NKN and the asynchronous case. Working together with NKN, we can improve the cutting edge of blockchain technology in general.
To fully enjoy the interactive Wolfram notebook with all the embedded source code and graphing tools, here is a link to the cloud notebook:
Wolfram Cloud Document
Edit description www.wolframcloud.com
About Stephen Wolfram

Dr. Stephen Wolfram
Stephen Wolfram is the creator of Mathematica, Wolfram|Alpha and the Wolfram Language; the author of A New Kind of Science; and the founder and CEO of Wolfram Research. Over the course of nearly four decades, he has been a pioneer in the development and application of computational thinking — and has been responsible for many discoveries, inventions and innovations in science, technology and business. Learn more at stephenwolfram.com.
About NKN
NKN is the new kind of P2P network connectivity protocol & ecosystem powered by a novel public blockchain. We use economic incentives to motivate Internet users to share network connection and utilize unused bandwidth. NKN’s open, efficient, and robust networking infrastructure enables application developers to build the decentralized Internet so everyone can enjoy secure, low cost, and universally accessible connectivity.

Home: https://nkn.org/
Email: [email protected]
Telegram: https://t.me/nknorg
Twitter: https://twitter.com/NKN_ORG
Medium: https://medium.com/nknetwork
Linkedin: https://www.linkedin.com/company/nknetwork/
Github: https://github.com/nknorg
Reddit: https://www.reddit.com/r/nknblockchain
Discord: https://discord.gg/yVCWmkC
YouTube: http://www.youtube.com/c/NKNORG